








Best Practices for Dealing With Log4j

Table of Contents
Since December 10, in a span of just 20 days, there have been four different vulnerabilities published against Log4j. Engineers who worked long hours to update their Log4j versions to 2.15.0 on December 11th, were told three days later that they needed to do it all over again and upgrade to version 2.16.0.
This is not sustainable.
And yet the risks are high. Looking backward, we see that Log4j has been vulnerable since 2013 to the kinds of attacks described in CVE-2021-44228. The vulnerability has been out in the world unmitigated for 8 years! Can we safely assume that it has not been exploited by advanced attackers for all this time? That would be a risky assumption.
Looking forward, we have every reason to believe that new vulnerabilities will be discovered in Log4j over the coming days, weeks or months. As my colleague pointed out in his blog last week, Log4j includes an abundance of features and configuration options, all of which introduces an abundance of possible breaches. The folks at CISA have said: “We expect this cycle of vulnerability-fix, vulnerability-fix will continue as attackers and researchers continue to focus on Log4j.”
Dependency update is not enough to thwart future risks
We believe that a reactive approach — upgrading dependencies when vulnerabilities like this are disclosed — is not a best practice for the code that you control. To prevent attacks now and in the future, and to avoid endless fire drills such as we have seen for the past few weeks, applications need to be designed with user input sanitization.
To understand why, let’s first look at how data flows in a Log4j attack (Fig 1).
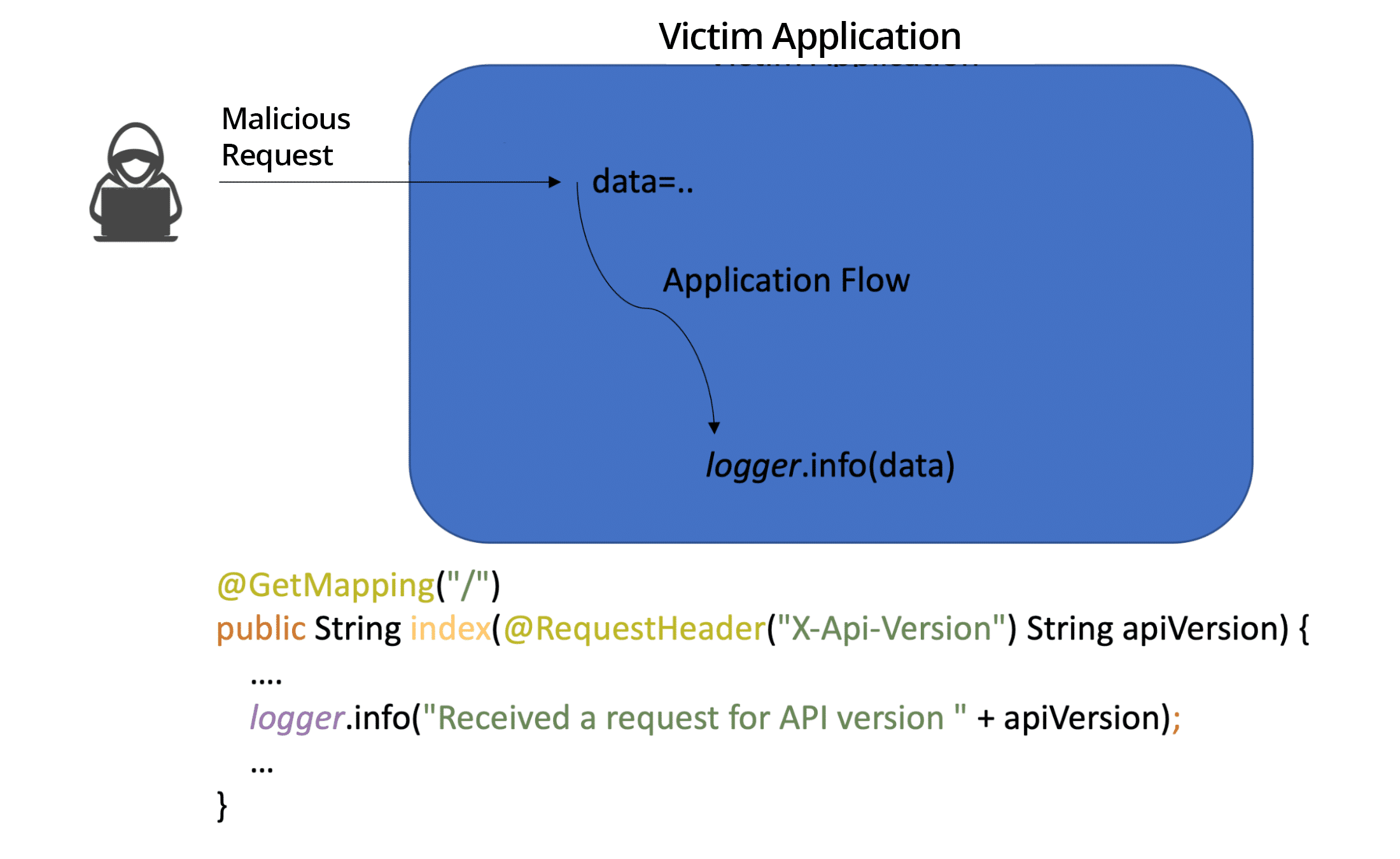
Figure 1: Log4j attacker to logger dataflow
The illustration above shows how the data flows from the attacker to the logger. With Log4Shell, an attacker who can control log messages or log message parameters can execute arbitrary code loaded from LDAP servers when message lookup substitution is enabled.
Looking more closely at the flow in Figure 1, we notice that the API call to the logger is a call to the abstract logger class that is usually provided by log4j-api. The actual implementation is usually provided by log4j-core, which is the concrete implementation of the logger.
The importance of sanitizing user input
Although the example in Fig 1 is strongly associated with LDAP and JNDI protocols, in practice CVE-2021-44228 boils down to something as simple as user input not being sanitized or validated before being used in applications.
In Fig 1 the apiVersion is passed to the logger without any sanitization process. Sanitizing or validating user input is one of the key pillars of Application Security. This is how we developers mitigate many serious CWEs, such as injection-type attacks. Sanitizing input before sending it to logs is described in CWE-117, which has been around for ages. It was submitted as a CWE in 2006 and described in a 2005 paper, Seven Pernicious Kingdoms: A Taxonomy of Software Security Errors: If developers had learned to sanitize or validate user input going into logs, CVE-2021-44228 would be harmless to the world.
To summarize what we have learned so far, an application might have numerous call sites (access points) to the logger, however a call to the logger is at risk if both of the following conditions are met:
1) The version of the logger implementation is vulnerable (in the example from figure 1 Log4J-core is suspected to be vulnerable)
2) Unsanitized user input is passed to the logger.
How to gauge the risk to your app at every log attempt
How do you determine whether the two conditions above are present, and thus, whether you are at risk?
The first condition is easily determined simply by running any competent software composition analysis tool that includes dependency trace analysis, such as Mend.
To explain the second condition, let’s first take a look at sanitized input. An example of sanitized input is a response to a map lookup, or any other safe API call. Here is an example of safe, sanitized code:
@GetMapping("/safe-sanitized")
public String safesanitized(@RequestHeader("X-Api-Version") String apiVersion) {
…
logger.info("Received a request for API version " + map.get(apiVersion));
…
}Figure 2: Safe, sanitized data sent to logger using a map.get API call
In the case described in Figure 2, the data that is logged is a result of a map API call, and the user input is just a key to that map. The data sent to the logger by the application are constant values inserted into the map object, not arbitrary user input. Therefore, this data input is safe, and no remediation is needed. However, since there is a data-flow path from the application input to the logger, most SAST tools will consider this flow as vulnerable. But a more advanced tool that includes data-flow analysis will not consider this code vulnerable.
In many cases, the log message will contain risky characters like JSON objects. Notice however that those will always be a result of some API call, hence condition 2 will not be met. To understand this scenario, consider the following Java code:
logger.info("My Json:" + new com.google.gson.Gson().toJson(myObject));Figure 3: Safe, sanitized data sent to logger using a toJson API call
In the case described in Figure 3, the log message will be a result of the Json API call. Condition 2 will not be met and this call to the logger will be considered as safe.
How to secure your user input to loggers
If both conditions mentioned above are met, your log access may be vulnerable, and a remediation is recommended. Upgrading to a newer version can only protect against known vulnerabilities. To future-proof your application security and prepare for emerging new vulnerabilities, we recommend another approach.
We suggest encoding all non-sanitized user data before it is passed to the logger, as was suggested long ago by CWE-117. For example, in the Java code in Fig 1, instead of submitting the apiVersion to the logger, the program can pass an encoded version of it.
In general, there are two options for encoding the user input: using a deny or allow list.
For demonstrating the deny list, consider the following Java code:
@GetMapping("/safe-deny-list")
public String safeindex(@RequestHeader("X-Api-Version") String apiVersion) {
…
logger.info("Received a request for API version " + log4jEncoder(apiVersion));
…
}
private String log4jEncoder(String apiVersion) {
String regex = "["+ "{}" + _risky_chars_set_ + "]";
apiVersion = apiVersion.replaceAll(regex,"_");
return apiVersion;Figure 4: Safe access to log using a deny list
In the example above the system has a set of predefined “bad” characters at risk. These characters will be replaced in the input string before sending them into the logger. For example, “{“ will be replaced by “_”, so a string of the form “{some data..” will be replaced by “_some data…”.
The drawback of this approach is that the characters at risk must be defined to cover all characters in all encodings formats such as utf-8, utf-7, … In this way, deny lists quickly become cumbersome. To overcome this problem, consider using an allow instead of a deny list. Here is an example:
@GetMapping("/safe-allow-list")
public String safeindexAlowList(@RequestHeader("X-Api-Version") String apiVersion) {
String regex = "[" + "^" + "a-zA-Z0-9" + whitespace_chars + "]";
…
logger.info("Received a request for API version " + apiVersion.replaceAll(regex,"_"));
…
}Figure 5: Safe access to the logger using an allow list
With the allow list approach, a set of “good” characters are defined. The logger can get any string containing these characters. However if a string contains a character which is excluded from this list, it will subsequently be replaced by a harmless symbol.
Optional: How to decode your safe encoding
The allow or deny list approach leads to losing some of the data when retrieving it from the log. For example, if the user sends some data such as “{ some data }” the logger will log the encoded version that will be “_some data _”. When retrieving the data from the log the curly brackets will be missing. Notice that this will happen only for the call sites that log a direct message from the user and not a message that is the response to an API call such as to Json(..). However, to preserve this data, the solution can be extended by replacing characters from the list with an encoded form of these characters. With this approach, when reading from the log a decode function can recover the original string.
Conclusion
Traditional SAST tools are commonly flagging CWE-117 as low severity and, as a result, many developers are sending user input straight into logs without any sanitization or validation. If developers would have to sanitize/validate user input before passing it into the logs, vulnerabilities like CVE-2021-44228 would be harmless. Some of the ‘blame’ for this can be attributed to the low severity flagging of CWE-117, which means that developers are not aware of this problem.
When and where will the next vulnerability be found? The problem extends far beyond the Log4j logger. Non-Java loggers and other log classes/modules/frameworks share this problem as well. Our recommendation is to sanitize any user input that flows into a logger by using allow or deny lists.
Get free tools to detect and fix Log4j vulnerabilities at our Log4j Resource Center.


